Chapter 4 Variable Selection
4.1 Functiondal regression with points of impact
4.1.1 State of Art
Nonparametric variable selection approach (NOVAS). NOVAS is quite expensive from a computational perspective, Frédéric Ferraty, Hall, and Vieu (2010).
A wavelet-based weighted LASSO functional linear (FWLASSO). FWLASSO requires transforming the original variables and assuming a linear model, Zhao, Chen, and Ogden (2015).
Berrendero, Cuevas, and Torrecilla (2016) use the Maxima-hunting proposal to choose the most relevant design points in functional classification setting.
4.1.2 Local maxima distance correlation approach (LMDC), (Ordóñez et al. 2018)
In this work we study the utility of distance correlation G. J. Székely, Rizzo, and Bakirov (2007) as an intrinsic method for variable selection.
Neither projection nor transformation of the variables is needed. Moreover, it is unnecessary to assume an a priori regression model.
LMDC approach consists in calculating the local maxima of the distance correlation along the curve.
4.1.3 LMDC Algorithm: LMDC.select() function
Calculate de distance correlation (DC) \(R(t) = \left \lbrace R(X(t_j),Y) \right\rbrace {_{j=1}^N}\), from the data \(\left \lbrace X_i (t_j),Y_i \right\rbrace _{i=1}^n\).
Calculate the LM of the \(\hat{\mathcal{R}} (t)\). Only the significant local maxima for a default level of significance are selected. Denoting the arguments values (argvals) of the local maxima a \(\tilde t_1,\tilde t_2,\ldots,\tilde t_{\tilde{N}}\) (\(\tilde{N}<N\)), we ordered them from highest to lowest values of DC, that is \(\hat{\mathcal{R}}(\tilde t_1) \geq \hat{ \mathcal{R}}(\tilde t_2) >\ldots \geq \hat {\mathcal{R}}(\tilde t_{\tilde{N}})\)
library(fda.usc)
pred2gsam <- fda.usc.devel:::pred2gsam
predict.classif <- fda.usc.devel:::predict.classif
predict.fregre.gsam <- fda.usc.devel:::predict.fregre.gsam data(tecator)
X.d2<-fdata.deriv(tecator[["absorp.fdata"]],
nderiv = 2)
colnames(X.d2[["data"]])<-paste0("X",round(X.d2[["argvals"]]))
dat <- data.frame("y"=tecator[["y"]][["Fat"]],X.d2[["data"]] )
tol<-.2
dc.raw <- LMDC.select("y",data = dat, tol = tol,pvalue = 0.05,
plot=F)
# Preselected impact points
covar<-names(dat)[-1][dc.raw[["maxLocal"]]]
covar## [1] "X933" "X1046" "X907" "X886" "X896" "X1010" "X1020" "X1030" "X945"
## [10] "X876" "X915" "X862" "X993"## [1] 134.1.4 LMDC Algorithm: LMDC.regre() function
- (Optionally) Check if the relationship between the reponse and the predictor variables is linear: \(H_0:\,Y=\big<X,\beta\big>+\epsilon\), versus a general alternative using a test of linearity proposed in Garcı́a-Portugués, González-Manteiga, and Febrero-Bande (2014).
##
## PCvM test for the functional linear model using optimal PLS basis
## representation
##
## data: Y=<X,b>+e
## PCvM statistic = 216.66, p-value < 2.2e-16## [1] 0Fit a regression model to the response of interest \(Y\) using the vector of covariates \(X(\tilde{t})=\{X(\tilde t_1), \ldots, X(\tilde{t}_{\tilde{N}})\}\). A linear model will be used if the null hypothesis is not rejected and a nonparametric (e.g. generalized additive model) model otherwise.
(Optionally) Once the type model has been selected, we propose to Apply a forward stepwise regression method to determine the significant covariates, taking advantage of the fact that the local maxima have been ordered. This means we start with a model with the first covariate (the one with the highest value of distance correlation), and the rest of the ordered covariates are added to the model in turn. This substantially reduces the computing time.
if (ftest$p.value > 0.05) { # Linear relationship, step-wise lm is recommended
out <- LMDC.regre(y = "y", covar = covar, data = dat, pvalue=.05, method ="lm")
} else {# Non-Linear relationship, step-wise gam is recommended
out <- LMDC.regre(y = "y", covar = covar, data = dat,pvalue=.05, method ="gam")}
out## $model
##
## Family: gaussian
## Link function: identity
##
## Formula:
## y ~ s(X933, k = 4) + s(X1046, k = 4) + s(X907, k = 4) + s(X886,
## k = 4) + s(X896, k = 4) + s(X1010, k = 4) + s(X1020, k = 4) +
## s(X1030, k = 4) + s(X945, k = 4) + s(X876, k = 4) + s(X915,
## k = 4) + s(X993, k = 4)
##
## Estimated degrees of freedom:
## 3.00 2.55 2.83 2.00 1.00 1.00 2.94
## 2.92 2.81 2.57 1.00 2.85 total = 28.48
##
## GCV score: 0.4403176
##
## $xvar
## [1] "X933" "X1046" "X907" "X886" "X896" "X1010" "X1020" "X1030" "X945"
## [10] "X876" "X915" "X993"
##
## $pred
## NULL
##
## $edf
## [1] 28.48142
##
## $nvar
## [1] 12Differences in mean square prediction error between linear (usign lm model) and non-linear (usign gam model) model
out <- LMDC.regre(y = "y", covar = covar, data = dat[1:165,],newdata=dat[166:215,], pvalue=.05, method ="lm")
mean((out$pred-dat$y[166:215])^2)## [1] 11.75474out <- LMDC.regre(y = "y", covar = covar, data = dat[1:165,],newdata=dat[166:215,], pvalue=.05, method ="gam")
mean((out$pred-dat$y[166:215])^2)## [1] 1.148573Binary classification example (Impact point selection, model estimation and prediction)
data(tecator)
X.d2<-fdata.deriv(tecator[["absorp.fdata"]],
nderiv = 2)
colnames(X.d2[["data"]])<-paste0("X",round(X.d2[["argvals"]]))
y2groups <- ifelse(tecator[["y"]][["Fat"]]<12,0,1)
dat <- data.frame("y2groups"=y2groups,X.d2[["data"]] )
tol<-.1
dc.raw <- LMDC.select("y2groups",data = dat, tol = tol,pvalue = 0.05,
plot=F)
# Preselected impact points
covar<-names(dat)[-1][dc.raw[["maxLocal"]]]
covar## [1] "X945" "X905" "X933" "X886" "X1020" "X876" "X1030" "X896" "X1046"
## [10] "X862" "X1010" "X915" "X965"## [1] 13# GLM model (using binomial family), other multivariate model can be used
ind <- 1:129
ldata<-list("df"=dat[ind,])
form.glm<-formula(paste0("y2groups~",paste0(covar,collapse="+")))
out.glm <- classif.glm(form.glm, data = ldata)
summary(out.glm)## - SUMMARY -
##
## -Probability of correct classification by group (prob.classification):
## 0 1
## 1 1
##
## -Confusion matrix between the theoretical groups (by rows)
## and estimated groups (by column)
##
## 0 1
## 0 58 0
## 1 0 71
##
## -Probability of correct classification: 1# Prediction
newldata<-list("df"=dat[-ind,])
pred.glm<-predict(out.glm,newldata)
# Confusion matrix
table(newldata$df$y2groups,pred.glm)## pred.glm
## 0 1
## 0 40 0
## 1 3 434.2 Variable selection in functional regression
Febrero-Bande, González-Manteiga, and Oviedo de la Fuente (2019) consider the problem of variable selection in regression models in the case of functional variables that may be mixed with other type of variables (scalar, multivariate, directional, etc.).
Our proposal begins with a simple null model and sequentially selects a new variable to be incorporated into the model based on the use of distance correlation proposed by (G. J. Székely, Rizzo, and Bakirov 2007). For the sake of simplicity, this paper only uses additive models.
\[ Y_i=\alpha+\sum_{j=1}^Jf_j({X_i^{(j)}})+\varepsilon_i,\quad i=1,\ldots,N \]
The proposed algorithm may assess the type of contribution (linear, non linear, …) of each variable. The algorithm has shown quite promising results when applied to simulations and real data sets.
4.2.1 State of Art
Stepwise regression, Akaike (1973). The main idea is to use some diagnostic tools, directly derived from the linear model, to evaluate the contribution of a new covariate and decide whether it should be included in the model. The final subset is usually constructed using: the forward and/or the backward selection.
Feature Selection using LASSO. The work by Tibshirani, 1996 proposing the LASSO estimator includes a \(l_1\)-type constraint for the coefficient vector \(\beta\). Several examples following the same line but using penalties or constraints such as: LARS (Efron et al. (2004)) and COSSO (Lin, Zhang, et al. (2006)). Each methods is based on a specific model, all the covariates must be included in the model at the same time and for functional data problems, the previous steps that commonly include variable standardization.
Berrendero, Cuevas, and Torrecilla (2016) use the Minimum Redundance Maximum Relevance (mRMR) procedure to choose the most relevant design points in functional classification setting.
A pure feature selection methods where the covariate is selected without a model. This is the approach employed in minimum Redundancy Maximum Relevance (mRMR), (Peng, Long, and Ding (2005)) where a new candidate covariate must have a great relevancy with the response while maintaining a lower redundancy with the covariates already selected in the model. he main advantage of this approach is that it is an incremental rule but the measures for redundancy and relevancy must be chosen in function of the regression model applied to ensure good predictive results in the final model. Berrendero, Cuevas, and Torrecilla (2018) used the Reproducing Kernel Hilbert Space (RKHS) for variable selection in FLM.
Boosting, see F. Ferraty and Vieu (2009) in a functional data context. Boosting selects at each step the best covariate/model with respect to the unexplained part of the response. The final prediction is constructed as a combination of the different steps.
Partial distance correlation (PDC): used in Yenigün and Rizzo (2015) for VS in multivariate linear models, a definition of PDC among \(X\) and \(Y\) given \(Z\) was introduced based on computing the distance correlation among the residuals of two models: \(Y\) respect to \(Z\) and \(X\) respect to \(Z\). PDC is constructed under linear relationship assumptions among variables. Its implementation only uses the distance matrices among elements of \(X\), \(Y\) and \(Z\) (variables should have a similar scale).
Specifically, \(Z\) (the variables already in the model) could be a mix of functional, scalar or multivariate variables where an appropriate distance using all of them must be hard to compute. Even restricting ourselves to the scalar case, those variables should have a similar scale.
4.2.2 Algorithm
All the previous solutions are not completely satisfactory in a functional data framework, specially when the number of possible covariates can be arbitrarily large. We are interested in an automatic regression procedure capable of dealing with a large number of covariates of different nature, possibly very closely related to one another.
The key of the whole procedure is the extensive use of the DC that presents two important advantages: the choice of the variate is made without considering a model and it is possible to compute this quantity for variates of different nature as it is only computed from distances. The distance correlation (DC) is computed among the residuals of the current model with each candidate. Taking into account that the residuals have the same nature as the response variable, the DC can always be computed at each step.
Our proposal is presented is a very general way, we have restricted ourselves to additive models that offer a balanced compromise between predictive ability and simplicity. The obtained results are quite promising in scenarios where no competitors are available because no other procedure can deal with variates of different nature in a homogeneous way.
The procedure was applied to a real problem related with the Iberian Energy Market (Price and Demand) where the number of possible covariates is really big. The algorithm was able to find synthetic regression models offering interesting insights about the relationship among the response and the covariates. The final selected models mix functional, scalar and categorical information.
Our algorithm can be formalized as follows:
Let \(Y\) the response and \(S=\{X^1,\ldots,X^p\}\) the set of all possible predictors.
Set \(\hat{Y}=\bar{Y}\), and let \(M^{(0)}=\emptyset\) the initial set of the variates included in the model. Set \(i=0\).
Compute the residuals of the current model: \(\hat{\varepsilon}=Y-\hat{Y}\).
Choose \(X^j\in S\) such that: 1) \(\mathcal{R}\{\hat{\varepsilon},X^j\}\ge \mathcal{R}\{\hat{\varepsilon},X^k\}, \forall k\ne j\in S\) and 2) the null hypothesis for the test of independence among \(\left\{X^j\right\}\) and \(\hat{\varepsilon}\) is rejected. IF NOT, END.
Update the sets \(M\) and \(S\): \(M^{(i+1)}=M^{(i)}\cup\{X^j\}\), and \(S=S\backslash\{X^j\}\).
Compute the new model for \(Y\) using \(M^{(i+1)}\) choosing the best contribution of the new covariate. Typically, there will be a catalog of all possible ways of constructing correct models with the variates in \(M^{(i+1)}\) fixing the contributions of the variates in \(M^{(i)}\) and adding the new one.
Analyze the contribution of \(X^j\) in the new model respect to the current:
IF this contribution is not relevant (typically comparing with the current model) THEN \(M^{(i+1)}=M^{(i+1)}\backslash\{X^j\}\) and the current model remains unalterable
ELSE the new model becomes the current model and provides new predictions (\(\hat{Y}\)). Along the paper we have employed an additive model: \(\hat{Y}=\bar{Y}+\sum_{m\in M}\hat{f}_m\left(X^{(m)}\right)\) where at each step \(\hat{f}_m\) could be linear or nonlinear.
Update the number of iterations: \(i=i+1\) and go to 3
END.
The current model is the final model with the variates included in \(M^{(i)}\). \(S\) is either the empty set or contains those variables that accept the null hypothesis of the test of independence respect to the residuals of the current model.
4.3 Binary classification example
Nt=250
Np=250
nB=100
Nvar <- 50
set.seed(1)
Xdat <- mariachi(Nt,Np,Nvar)
Xtrain <- Xdat$Xtrain
Xtest <- Xdat$Xtest
ytrain <- Xtrain$grupo
ytest <- Xtest$grupo
pairs(Xtrain[,2:6],col=ytrain)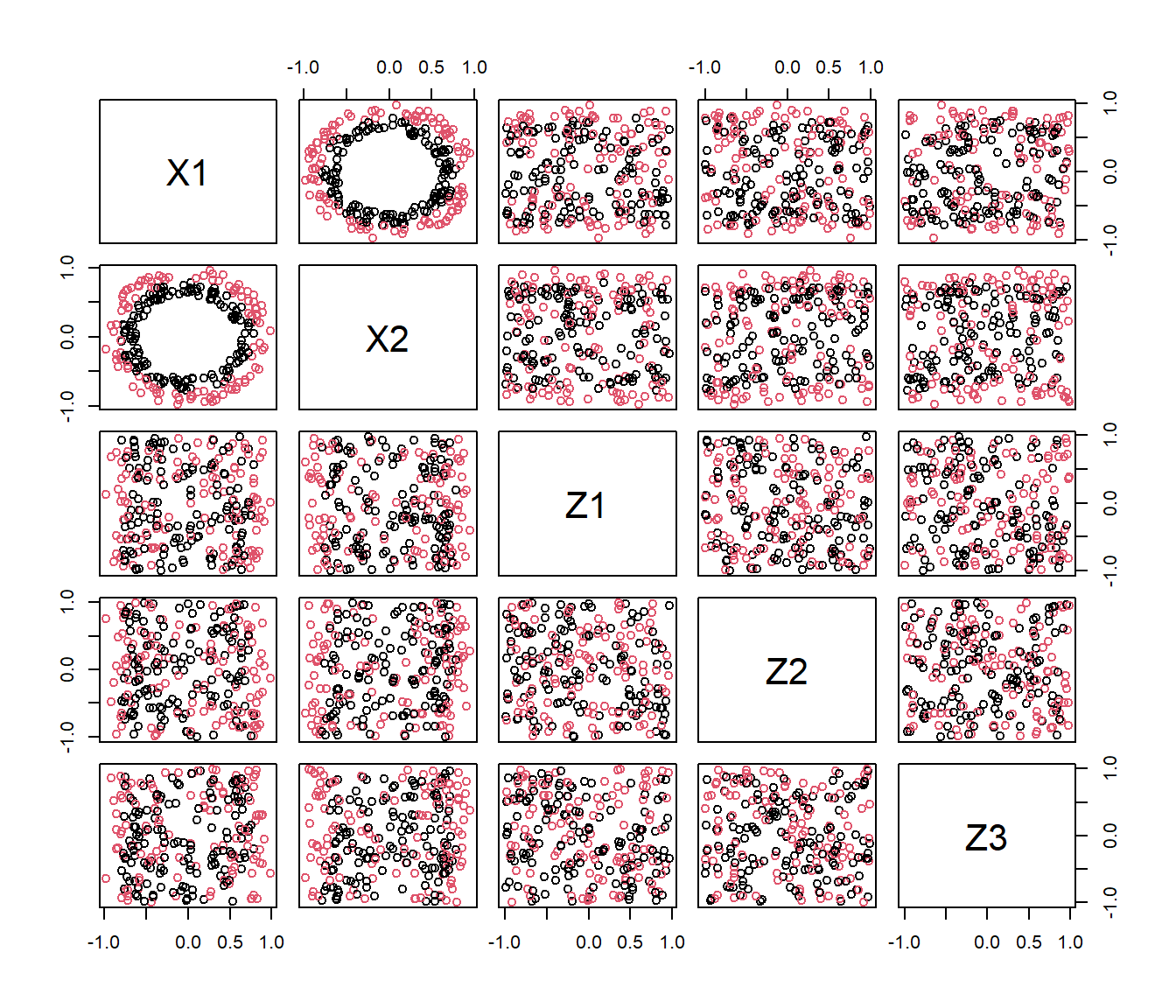
## [1] "grupo" "X1" "X2" "Z1" "Z2" "Z3" "Z4" "Z5" "Z6"
## [10] "Z7" "Z8" "Z9" "Z10" "Z11" "Z12" "Z13" "Z14" "Z15"
## [19] "Z16" "Z17" "Z18" "Z19" "Z20" "Z21" "Z22" "Z23" "Z24"
## [28] "Z25" "Z26" "Z27" "Z28" "Z29" "Z30" "Z31" "Z32" "Z33"
## [37] "Z34" "Z35" "Z36" "Z37" "Z38" "Z39" "Z40" "Z41" "Z42"
## [46] "Z43" "Z44" "Z45" "Z46" "Z47"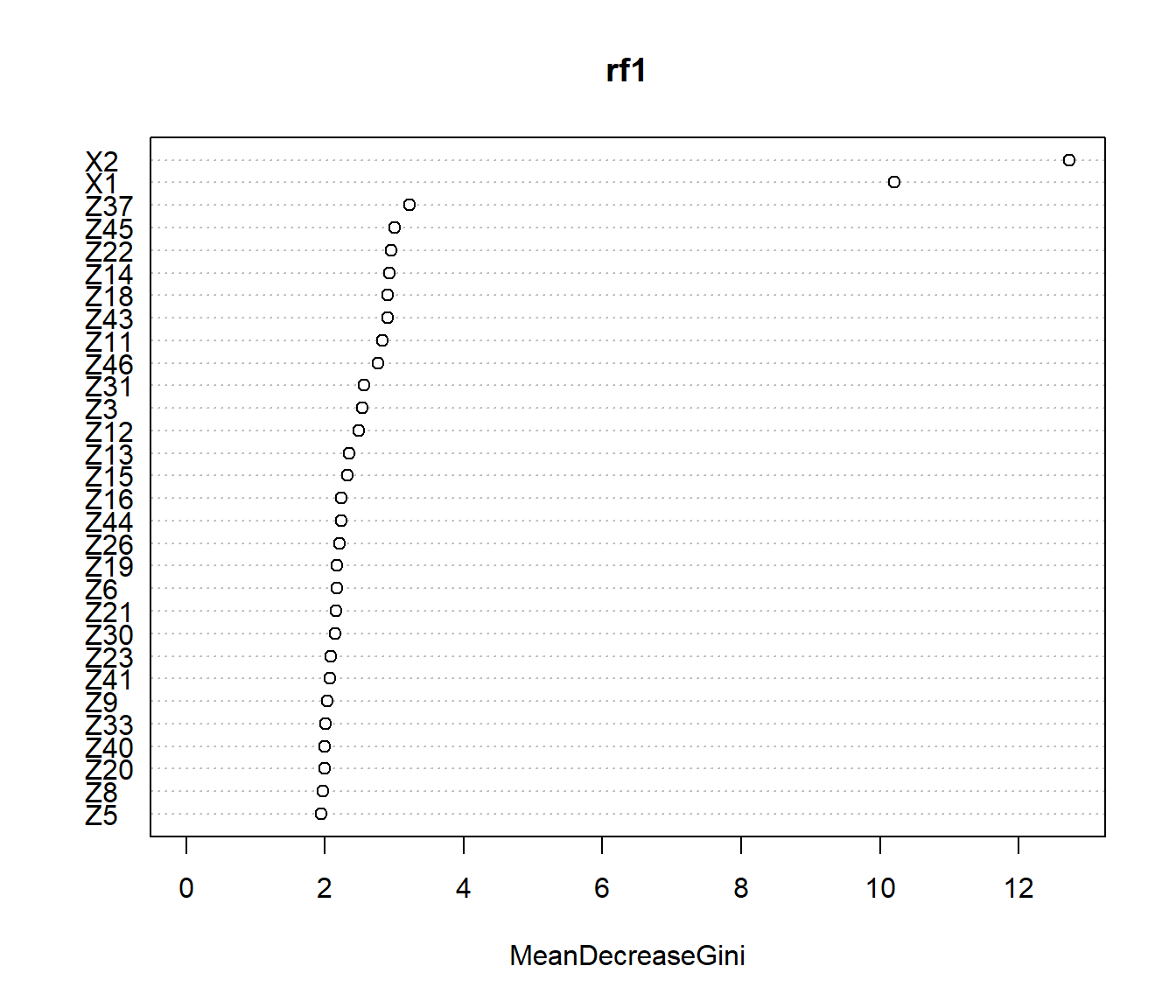
## accuracy
## 0.672## pred.rf1
## ytest 1 2
## 1 95 14
## 2 68 73rf.vs <- fda.usc.devel:::classif.ML.vs(ldata(mdat),"grupo",classif="classif.randomForest")
summary(rf.vs)## - SUMMARY -
##
## -Probability of correct classification by group (prob.classification):
## [1] 0.9185185 0.8869565
##
## -Confusion matrix between the theoretical groups (by rows)
## and estimated groups (by column)
##
## 1 2
## 1 124 11
## 2 13 102
##
## -Probability of correct classification: 0.904## X1 X2 Z1 Z2 Z3 Z4 Z5 Z6 Z7 Z8 Z9 Z10 Z11 Z12 Z13 Z14 Z15 Z16 Z17 Z18
## 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## Z19 Z20 Z21 Z22 Z23 Z24 Z25 Z26 Z27 Z28 Z29 Z30 Z31 Z32 Z33 Z34 Z35 Z36 Z37 Z38
## 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## Z39 Z40 Z41 Z42 Z43 Z44 Z45 Z46 Z47
## 0 0 0 0 0 0 0 0 0## [1] "X2" "X1"## X1 X2 Z1 Z2 Z3 Z4 Z5 Z6 Z7 Z8 Z9 Z10 Z11 Z12 Z13 Z14 Z15 Z16 Z17
## 1 0.016 0.018 0 0 0 0 0 0 0 0 0 0 0.01 0 0 0.010 0 0 0
## 2 0.032 0.000 0 0 0 0 0 0 0 0 0 0 0.00 0 0 0.000 0 0 0
## 3 0.000 0.000 0 0 0 0 0 0 0 0 0 0 0.00 0 0 0.011 0 0 0
## 4 0.000 0.000 0 0 0 0 0 0 0 0 0 0 0.00 0 0 0.011 0 0 0
## 5 0.000 0.000 0 0 0 0 0 0 0 0 0 0 0.00 0 0 0.000 0 0 0
## 6 0.000 0.000 0 0 0 0 0 0 0 0 0 0 0.00 0 0 0.000 0 0 0
## Z18 Z19 Z20 Z21 Z22 Z23 Z24 Z25 Z26 Z27 Z28 Z29 Z30 Z31 Z32 Z33 Z34 Z35
## 1 0.015 0 0 0 0.013 0 0 0 0 0 0 0 0 0.00 0 0 0 0
## 2 0.000 0 0 0 0.000 0 0 0 0 0 0 0 0 0.01 0 0 0 0
## 3 0.000 0 0 0 0.000 0 0 0 0 0 0 0 0 0.00 0 0 0 0
## 4 0.000 0 0 0 0.000 0 0 0 0 0 0 0 0 0.00 0 0 0 0
## 5 0.000 0 0 0 0.000 0 0 0 0 0 0 0 0 0.00 0 0 0 0
## 6 0.000 0 0 0 0.000 0 0 0 0 0 0 0 0 0.00 0 0 0 0
## Z36 Z37 Z38 Z39 Z40 Z41 Z42 Z43 Z44 Z45 Z46 Z47
## 1 0 0.000 0 0 0 0 0 0 0 0 0 0
## 2 0 0.000 0 0 0 0 0 0 0 0 0 0
## 3 0 0.016 0 0 0 0 0 0 0 0 0 0
## 4 0 0.000 0 0 0 0 0 0 0 0 0 0
## 5 0 0.000 0 0 0 0 0 0 0 0 0 0
## 6 0 0.000 0 0 0 0 0 0 0 0 0 0## accuracy
## 0.896## pred.rf.vs
## ytest 1 2
## 1 103 6
## 2 20 121predictors <- names(mdat)[-1]
form <- formula(paste0("grupo~",paste0("s(",predictors,")",collapse="+")))
form## grupo ~ s(X1) + s(X2) + s(Z1) + s(Z2) + s(Z3) + s(Z4) + s(Z5) +
## s(Z6) + s(Z7) + s(Z8) + s(Z9) + s(Z10) + s(Z11) + s(Z12) +
## s(Z13) + s(Z14) + s(Z15) + s(Z16) + s(Z17) + s(Z18) + s(Z19) +
## s(Z20) + s(Z21) + s(Z22) + s(Z23) + s(Z24) + s(Z25) + s(Z26) +
## s(Z27) + s(Z28) + s(Z29) + s(Z30) + s(Z31) + s(Z32) + s(Z33) +
## s(Z34) + s(Z35) + s(Z36) + s(Z37) + s(Z38) + s(Z39) + s(Z40) +
## s(Z41) + s(Z42) + s(Z43) + s(Z44) + s(Z45) + s(Z46) + s(Z47)ldat <- ldata(mdat)
# gsam <- classif.gsam(form,data=ldat)
# Error in gam(formula = as.formula(pf), data = XX, family = family) : Model has more coefficients than data
form <- formula(paste0("grupo~",paste0("s(",predictors,",k=5)",collapse="+")))
ldat <- ldata(mdat)
gsam <- classif.gsam(form,data=ldat)
pred.gsam <- predict(gsam,ldata(newmdat))
cat2meas(ytest,pred.gsam)## accuracy
## 0.896## pred.gsam
## ytest 1 2
## 1 97 12
## 2 14 127## - SUMMARY -
##
## -Probability of correct classification by group (prob.classification):
## 1 2
## 1 1
##
## -Confusion matrix between the theoretical groups (by rows)
## and estimated groups (by column)
##
## 1 2
## 1 135 0
## 2 0 115
##
## -Probability of correct classification: 1## X1 X2 Z1 Z2 Z3 Z4 Z5 Z6 Z7 Z8 Z9 Z10 Z11 Z12 Z13 Z14 Z15 Z16 Z17 Z18
## 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## Z19 Z20 Z21 Z22 Z23 Z24 Z25 Z26 Z27 Z28 Z29 Z30 Z31 Z32 Z33 Z34 Z35 Z36 Z37 Z38
## 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## Z39 Z40 Z41 Z42 Z43 Z44 Z45 Z46 Z47
## 0 0 0 0 0 0 0 0 0## [1] "X2" "X1"## accuracy
## 0.984## pred.gsam.vs
## ytest 1 2
## 1 106 3
## 2 1 1404.4 Hyperspectral images example
During the last years, the use of hyperspectral sensors has been extended to a great variety of applications such as discrimination among different land cover classes in remote sensing images.
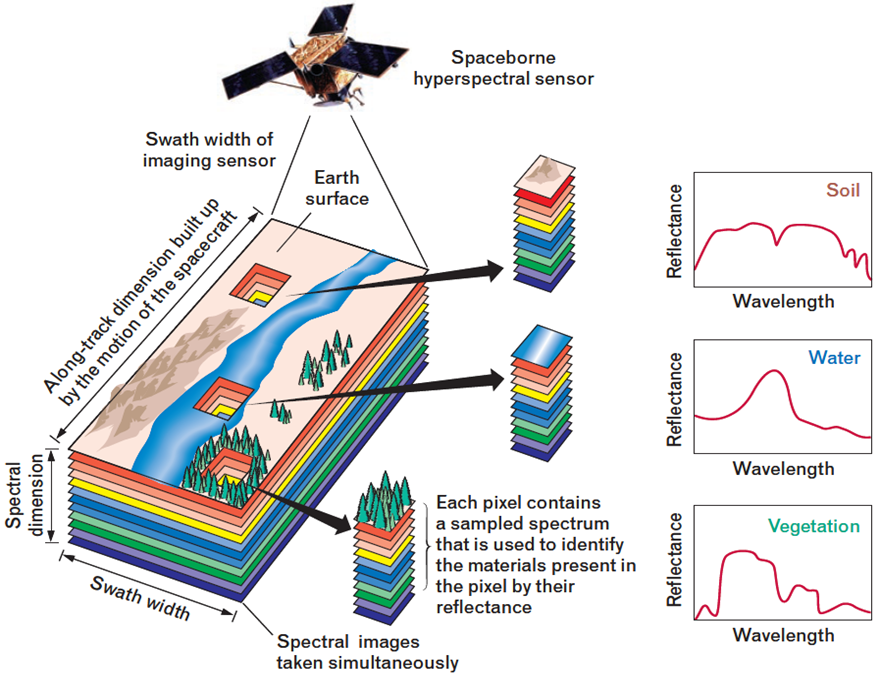
4.4.1 Hyperspectral Data set: Pavia University
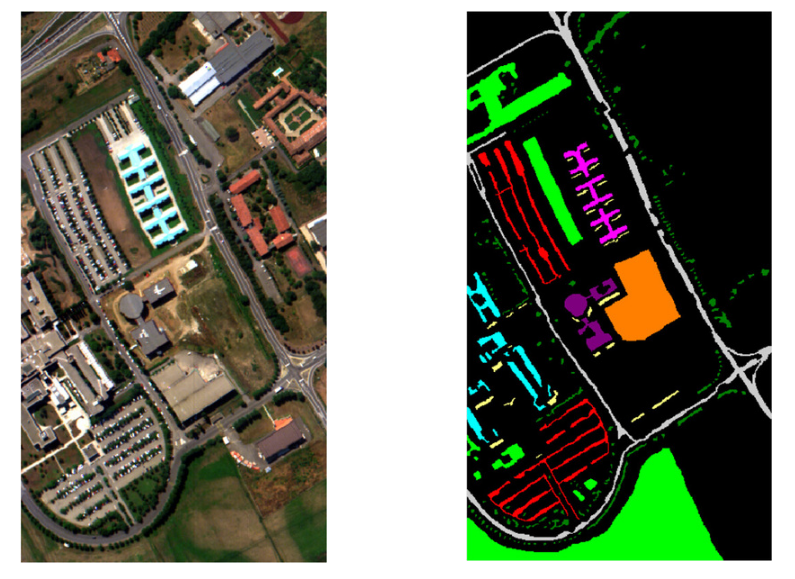
This is a remote sensing image obtained by the 103-band ROSIS sensor from the University of Pavia (Pavia Univ.), with a spatial dimension of 610 × 340 pixels
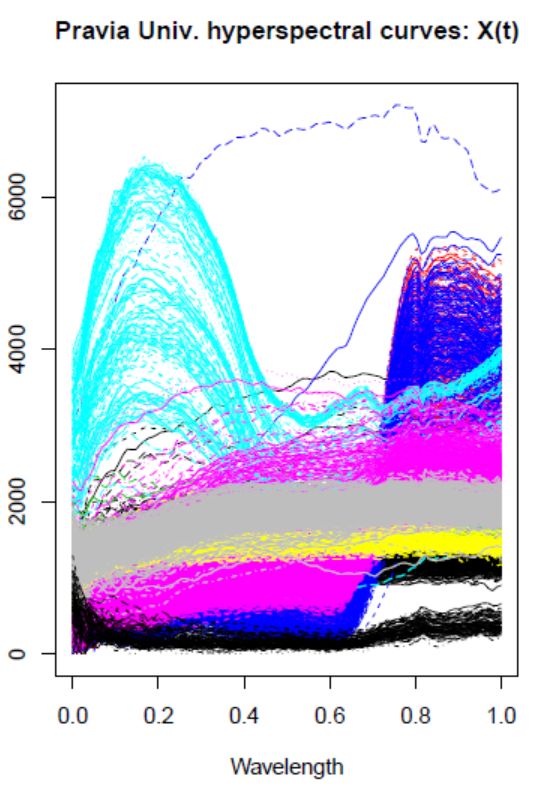
4.4.2 Hyperspectral images
In the University of Pavia image, 300 pixels for each class were chosen for training, and the rest were used as a test set.
1 2 3 4 5 6 7 8 9
6631 18649 2099 3064 1345 5029 1330 3682 947
[1] “Training”
1 2 3 4 5 6 7 8 9
300 300 300 300 300 300 300 300 300
[1] “Test”
yy
1 2 3 4 5 6 7 8 9
797 2308 244 324 119 589 117 424 78
names<-c(“Asphalt”,“Meadows”,“Gravel”,“Trees”,“Metal sheets”,“Bare Soil”,“Bitumen”,“Bricks”,“Shadows”)
``` r
# scalar covariates
names(ltest$df);
[1] "y" "icol" "irow" "z0" "z0.1" "z0.2" "z0.29" "z0.39" "z0.49" "z0.59" "z0.69" "z0.78"
[13] "z0.88" "z0.98"
# functional covariates
names(ltest)[-1]
[1] "x" "x.d1"
gsam1 <- classif.gsam(y ~ icol+irow ,data=ltrain2)
There were 18 warnings (use warnings() to see them)
summary(gsam1)
- SUMMARY -
-Probability of correct classification by group (prob.classification):
1 2 3 4 5 6 7 8 9
0.00 0.47 0.62 0.00 0.99 0.92 0.72 0.34 0.01
-Confusion matrix between the theoretical groups (by rows)
and estimated groups (by column)
1 2 3 4 5 6 7 8 9
1 0 12 11 0 23 43 0 9 2
2 0 47 11 0 23 19 0 0 0
3 0 0 62 0 0 0 0 38 0
4 0 19 14 0 29 27 0 9 2
5 1 0 0 0 99 0 0 0 0
6 2 0 0 6 0 92 0 0 0
7 11 0 0 12 0 0 72 0 5
8 0 20 21 0 15 0 4 34 6
9 2 7 38 14 14 11 7 6 1
-Probability of correct classification: 0.4522
pred.gsam1 <- predict(gsam1,ltest)
cat2meas(ytest,pred.gsam1)
[1] 0.439
table(ytest,pred.gsam1)
pred.gsam1
ytest 1 2 3 4 5 6 7 8 9
1 0 61 52 0 121 174 0 22 16
2 0 639 186 0 321 168 16 2 0
3 0 0 92 0 0 0 0 51 0
4 0 38 17 0 74 53 3 21 8
5 1 0 0 0 103 0 0 0 0
6 5 0 0 37 0 325 0 0 0
7 12 0 0 16 0 0 68 0 1
8 0 49 39 0 24 0 9 89 14
9 6 5 11 6 11 10 14 9 1
gsam1 <- classif.gsam(y ~ s(icol) + s(irow) ,data=ltrain2)
summary(gsam1)
- SUMMARY -
-Probability of correct classification by group (prob.classification):
1 2 3 4 5 6 7 8 9
0.00 0.47 0.62 0.00 0.99 0.92 0.72 0.34 0.01
-Confusion matrix between the theoretical groups (by rows)
and estimated groups (by column)
1 2 3 4 5 6 7 8 9
1 0 12 11 0 23 43 0 9 2
2 0 47 11 0 23 19 0 0 0
3 0 0 62 0 0 0 0 38 0
4 0 19 14 0 29 27 0 9 2
5 1 0 0 0 99 0 0 0 0
6 2 0 0 6 0 92 0 0 0
7 11 0 0 12 0 0 72 0 5
8 0 20 21 0 15 0 4 34 6
9 2 7 38 14 14 11 7 6 1
-Probability of correct classification: 0.4522
pred.gsam1 <- predict(gsam1,ltest)
cat2meas(ytest,pred.gsam1)
[1] 0.439
table(ytest,pred.gsam1)
pred.gsam1
ytest 1 2 3 4 5 6 7 8 9
1 0 61 52 0 121 174 0 22 16
2 0 639 186 0 321 168 16 2 0
3 0 0 92 0 0 0 0 51 0
4 0 38 17 0 74 53 3 21 8
5 1 0 0 0 103 0 0 0 0
6 5 0 0 37 0 325 0 0 0
7 12 0 0 16 0 0 68 0 1
8 0 49 39 0 24 0 9 89 14
9 6 5 11 6 11 10 14 9 1
gsam1 <- classif.gsam(y ~ s(x) ,data=ltrain2)
summary(gsam1)
- SUMMARY -
-Probability of correct classification by group (prob.classification):
1 2 3 4 5 6 7 8 9
0.62 0.78 0.64 0.97 1.00 0.25 0.82 0.71 1.00
-Confusion matrix between the theoretical groups (by rows)
and estimated groups (by column)
1 2 3 4 5 6 7 8 9
1 62 0 4 0 0 2 27 5 0
2 0 78 3 13 0 6 0 0 0
3 2 1 64 0 0 0 7 26 0
4 0 2 0 97 0 1 0 0 0
5 0 0 0 0 100 0 0 0 0
6 0 56 1 2 0 25 0 16 0
7 15 0 3 0 0 0 82 0 0
8 1 1 12 0 0 6 9 71 0
9 0 0 0 0 0 0 0 0 100
-Probability of correct classification: 0.7544
pred.gsam1 <- predict(gsam1,ltest)
cat2meas(ytest,pred.gsam1)
[1] 0.7016667
table(ytest,pred.gsam1)
pred.gsam1
ytest 1 2 3 4 5 6 7 8 9
1 281 2 36 0 2 3 111 11 0
2 0 1001 27 186 0 116 0 2 0
3 4 1 103 0 0 0 7 28 0
4 0 7 0 207 0 0 0 0 0
5 0 0 0 0 104 0 0 0 0
6 1 215 11 5 0 90 0 45 0
7 8 1 1 0 0 0 87 0 0
8 2 3 32 0 0 11 17 159 0
9 0 0 0 0 0 0 0 0 73
gsam1 <- classif.gsam(y ~ s(icol) + s(irow) + s(x) ,data=ltrain2)
summary(gsam1)
- SUMMARY -
-Probability of correct classification by group (prob.classification):
1 2 3 4 5 6 7 8 9
0.49 0.80 0.75 0.94 1.00 0.78 0.84 0.74 1.00
-Confusion matrix between the theoretical groups (by rows)
and estimated groups (by column)
1 2 3 4 5 6 7 8 9
1 49 0 10 0 0 7 30 4 0
2 0 80 0 10 0 10 0 0 0
3 0 1 75 0 0 0 0 24 0
4 0 4 0 94 0 2 0 0 0
5 0 0 0 0 100 0 0 0 0
6 1 16 0 2 0 78 0 3 0
7 16 0 0 0 0 0 84 0 0
8 0 2 20 0 0 0 4 74 0
9 0 0 0 0 0 0 0 0 100
-Probability of correct classification: 0.8156
pred.gsam1 <- predict(gsam1,ltest)
cat2meas(ytest,pred.gsam1)
[1] 0.7766667
table(ytest,pred.gsam1)
pred.gsam1
ytest 1 2 3 4 5 6 7 8 9
1 236 1 46 0 2 43 115 3 0
2 0 1026 1 192 0 112 0 1 0
3 0 1 121 0 0 0 1 20 0
4 0 6 0 207 0 1 0 0 0
5 0 0 0 0 104 0 0 0 0
6 2 44 0 5 0 308 0 8 0
7 6 1 0 0 0 0 90 0 0
8 4 3 36 0 0 0 16 165 0
9 0 0 0 0 0 0 0 0 73
gsam.vs <- classif.gsam.vs(ltrain2,"y")
gsam.vs$i.predictor
icol irow z0 z0.1 z0.2 z0.29 z0.39 z0.49 z0.59 z0.69 z0.78 z0.88 z0.98 x x.d1
1 1 0 0 0 0 0 0 0 1 0 0 0 1 1
gsam.vs$ipredictor
[1] "x" "z0.69" "icol" "x.d1" "irow"
round(gsam.vs$dcor,2)
icol irow z0 z0.1 z0.2 z0.29 z0.39 z0.49 z0.59 z0.69 z0.78 z0.88 z0.98 x x.d1
1 0.20 0.18 0.33 0.43 0.44 0.44 0.42 0.37 0.36 0.38 0.42 0.43 0.43 0.58 0.43
2 0.07 0.06 0.04 0.06 0.07 0.07 0.07 0.06 0.06 0.08 0.06 0.06 0.06 0.00 0.05
3 0.07 0.06 0.04 0.06 0.06 0.07 0.06 0.06 0.06 0.00 0.05 0.05 0.06 0.00 0.05
4 0.00 0.03 0.02 0.04 0.04 0.04 0.04 0.03 0.03 0.00 0.04 0.04 0.04 0.00 0.04
5 0.00 0.03 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
6 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
summary(gsam.vs)
- SUMMARY -
-Probability of correct classification by group (prob.classification):
1 2 3 4 5 6 7 8 9
0.72 0.84 0.82 0.94 1.00 0.86 0.88 0.73 1.00
-Confusion matrix between the theoretical groups (by rows)
and estimated groups (by column)
1 2 3 4 5 6 7 8 9
1 72 0 5 0 0 3 15 5 0
2 0 84 0 7 0 8 0 1 0
3 0 1 82 0 0 0 1 16 0
4 0 4 0 94 0 2 0 0 0
5 0 0 0 0 100 0 0 0 0
6 0 9 0 1 0 86 0 4 0
7 12 0 0 0 0 0 88 0 0
8 2 0 23 0 0 1 1 73 0
9 0 0 0 0 0 0 0 0 100
-Probability of correct classification: 0.8656
pred.gsam.vs <- predict(gsam.vs,ltest)
cat2meas(ytest,pred.gsam.vs)
[1] 0.8106667
table(ytest,pred.gsam.vs)
pred.gsam.vs
ytest 1 2 3 4 5 6 7 8 9
1 290 1 38 0 0 31 79 7 0
2 3 1096 1 105 0 118 0 9 0
3 0 1 117 0 0 0 2 23 0
4 0 9 0 201 0 4 0 0 0
5 0 0 0 0 104 0 0 0 0
6 1 47 0 2 0 307 0 10 0
7 16 0 0 0 0 0 80 1 0
8 8 3 43 0 0 1 5 164 0
9 0 0 0 0 0 0 0 0 734.4.3 Pravia Univ. Results
| Method | \(x\)-pos., \(y\)-pos. | \(X(t)\) | \(X(t)\), \(x\)-pos., \(y\)-pos. |
|---|---|---|---|
| (F)GLM\(+\)MaxProb | 0.4626 | 0.5898 | 0.7802 |
| (F)GLM\(+\)MajVot | 0.4600 | 0.6926 | 0.9022 |
| (F)GAM\(+\)MaxProb | 0.7070 | 0.7384 | 0.9768 |
| (F)GAM \(+\)MajVot | 0.7662 | 0.7824 | 0.9846 |
4.4.4 Functional data example
data(tecator)
y=tecator$y$Fat
# Potential functional covariates
x=tecator$absorp.fdata
x1<-fdata.deriv(x)
x2<-fdata.deriv(x,nderiv=2)
# Potential factor covariates
xcat0<-cut(rnorm(length(y)),4)
xcat1<-cut(tecator$y$Protein,4)
xcat2<-cut(tecator$y$Water,4)
ind <- 1:129
# 3 functionals (x,x1,x2), 3 factors (xcat0, xcat1, xcat2)
# and 100 potential scalars covariates (impact poitns of x1)
dat <- data.frame("Fat"=y, x1$data, xcat1, xcat2)
ldat <- list("df"=dat[ind,],"x"=x[ind,],"x1"=x1[ind,],"x2"=x2[ind,])
# Time consuming
res.gam1<-fregre.gsam.vs(data=ldat,y="Fat")
summary(res.gam1$model)## Fat x2.PC1 x2.PC2 x2.PC3
## Min. : 0.90 Min. :-0.0033724 Min. :-3.094e-03 Min. :-0.0032994
## 1st Qu.: 7.70 1st Qu.:-0.0023729 1st Qu.:-7.134e-04 1st Qu.:-0.0001902
## Median :14.60 Median :-0.0009539 Median :-2.468e-05 Median : 0.0001020
## Mean :18.24 Mean : 0.0000000 Mean : 0.000e+00 Mean : 0.0000000
## 3rd Qu.:27.80 3rd Qu.: 0.0017247 3rd Qu.: 6.696e-04 3rd Qu.: 0.0002731
## Max. :49.10 Max. : 0.0095969 Max. : 6.243e-03 Max. : 0.0034894
## x2.PC4
## Min. :-1.076e-03
## 1st Qu.:-1.076e-04
## Median : 2.944e-05
## Mean : 0.000e+00
## 3rd Qu.: 1.294e-04
## Max. : 1.125e-03# Prediction like fregre.gsam()
newldat <- list("df"=dat[-ind,],"x"=x[-ind,],"x1"=x1[-ind,],"x2"=x2[-ind,])
pred.gam1<-predict(res.gam1,newldat)
plot(dat[-ind,"Fat"],pred.gam1)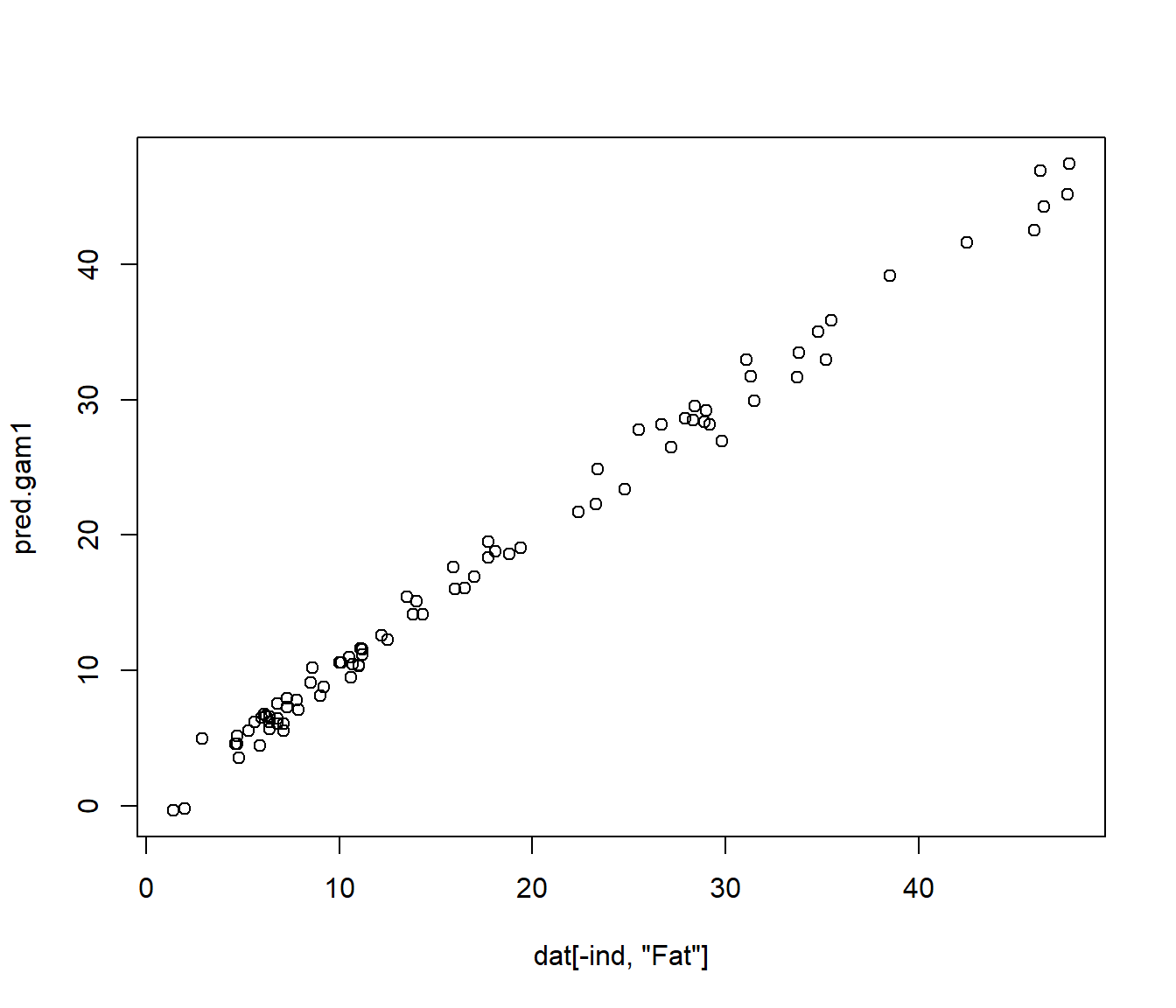
4.5 Optimum Multiscale Selection in 3D Point Cloud Classification (Oviedo-de la Fuente et al. 2021)
Supervised classification of 3D point clouds using machine learning algorithms and handcrafted local features as covariates frequently depends on the size of the neighborhood (scale) around each point used to determine those features. It is therefore crucial to estimate the scale or scales providing the best classification results. In this work, we propose three methods to estimate said scales, all of them based on calculating the maximum values of the distance correlation (DC) functions between the features and the label assigned to each point. The performance of the methods was tested using simulated data, and the method presenting the best results was applied to a benchmark data set for point cloud classification. This method consists of detecting the local maximums of DC functions previously smoothed to avoid choosing scales that are very close to each other. Five different classifiers were used: linear discriminant analysis, support vector machines, random forest, multinomial logistic regression and multilayer perceptron neural network. The results obtained were compared with those from other strategies available in the literature, being favorable to our approach.
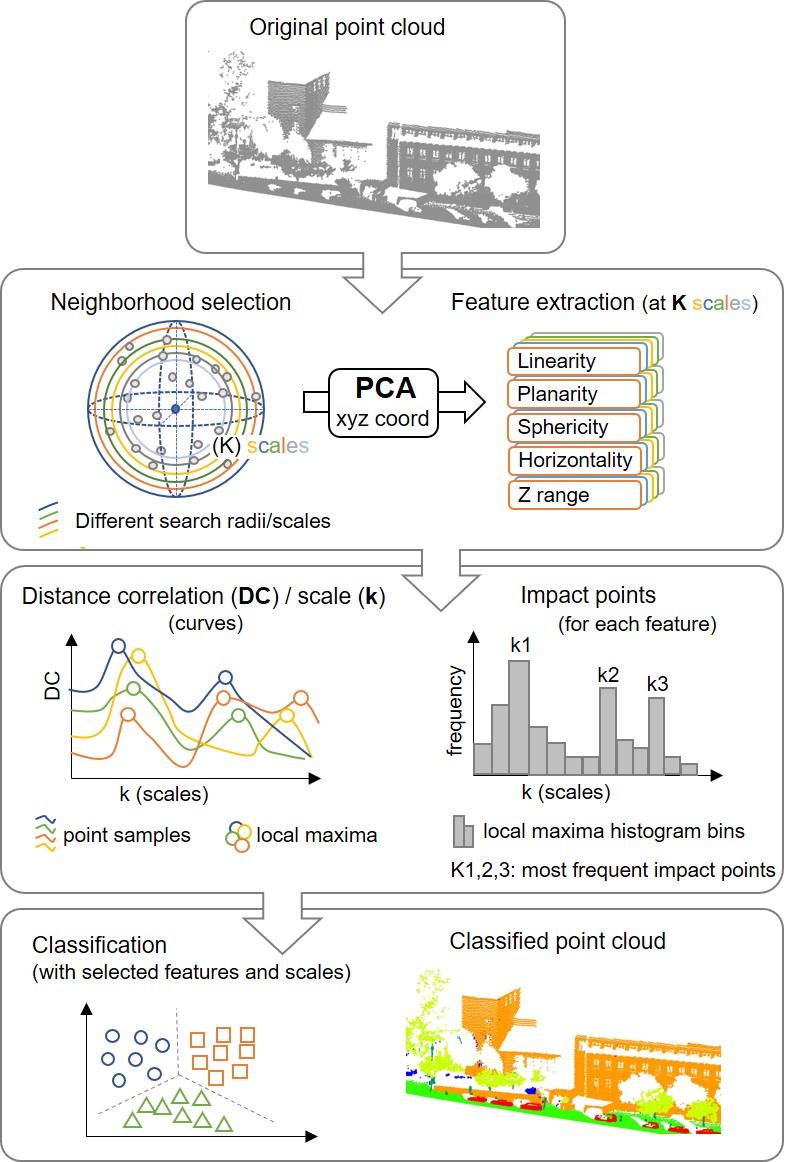
Figure 4.1: Urban scene
Oviedo-de la Fuente, M.; Cabo, C.; Ordóñez, C.; Roca-Pardiñas, J. A Distance Correlation Approach for Optimum Multiscale Selection in 3D Point Cloud Classification. Mathematics 2021, 9, 1328. https://doi.org/10.3390/math9121328
- Working paper
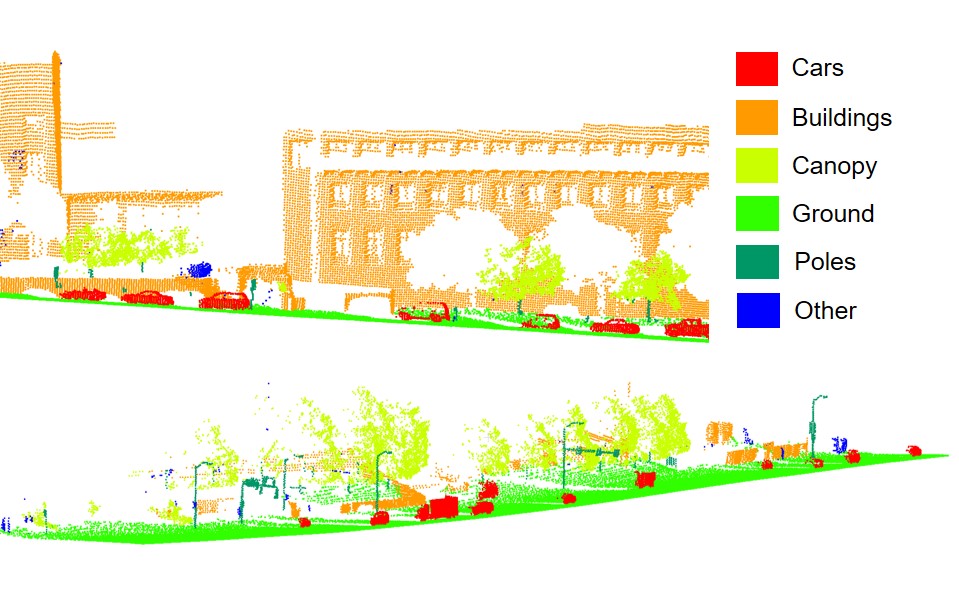
Figure 4.2: Forest scene
4.6 Model Comparison
Table collects the results of these fitted models. Recall that RMSE and MAE were calculated using 10-fold cross-validation. AIC and \(R^2_{adj}\) were computed using a model fitted with all available data.
| Model | RMSE | \(\sigma_{\mathrm{RMSE}}\) | MAE | \(\sigma_{\mathrm{MAE}}\) | AIC | \(R^2_{adj}\) |
|---|---|---|---|---|---|---|
| M1 | 40.83 | 7.28 | 24.81 | 4.01 | 20254 | 79.38% |
| M2 | 57.87 | 35.23 | 25.28 | 4.99 | 19342 | 87.90% |
| M3 | 34.95 | 6.36 | 22.34 | 3.03 | 18626 | 86.70% |